هستههای CUDA نهتنها یک بخش سختافزاری ساده در کارتهای گرافیک شرکت NVIDIA نیستند، بلکه نماد یک تحول عظیم در دنیای پردازش دادهها و محاسبات موازی محسوب میشوند. اگر به عقب برگردیم و سالهای قبل از ظهور CUDA را مرور کنیم، میبینیم که کارتهای گرافیک عمدتاً با هدف یک کار اصلی طراحی شده بودند: رندر و پردازش تصاویر گرافیکی برای نمایش بهتر بازیها و محیطهای سهبعدی. قدرت پردازشی آنها فقط محدود به محاسبات مربوط به گرافیک بود و اغلب در خارج از این حوزه استفاده نمیشد.
اما با معرفی CUDA، مفهوم GPU Computing یا همان «پردازش با استفاده از کارت گرافیک» وارد جریان اصلی محاسبات شد. این فناوری، یک مدل برنامهنویسی و یک معماری سختافزاری هماهنگ ارائه کرد که به برنامهنویسان اجازه میدهد از قدرت خام پردازندههای گرافیکی برای انجام انواع پردازشهای عمومی استفاده کنند. به عبارت ساده، CUDA، کارت گرافیک را از یک «دستگاه مخصوص نمایش تصویر» به یک «ماشین چندمنظوره قدرتمند» تبدیل کرد.
گذر از CPU به GPU در حل مسائل سنگین
تا پیش از این تحول، پردازشهای سنگین علمی، شبیهسازیها یا پردازش دادههای عظیم، عمدتاً بر دوش پردازندههای مرکزی (CPU) انجام میگرفتند. پردازندههای مرکزی بهطور کلی برای وظایف عمومی بهینه شدهاند و تعداد هستههای محدودی دارند. در مقابل، پردازندههای گرافیکی دارای صدها یا حتی هزاران هسته کوچکتر هستند که میتوانند تعداد بسیار زیادی پردازش را بهطور همزمان انجام دهند. CUDA این قابلیت ذاتی GPU را به شکلی قابل برنامهریزی و انعطافپذیر برای کاربردهای غیرگرافیکی در دسترس قرار داد.
مدل برنامهنویسی CUDA
یکی از مهمترین جنبههای انقلاب CUDA، مدل برنامهنویسی آن است. NVIDIA با ارائه مجموعهای از توابع و APIها در قالب CUDA Toolkit این امکان را فراهم کرده که زبان برنامهنویسی C/C++ و فرمتهای مشابه بتوانند مستقیماً با GPU ارتباط برقرار کنند. این ارتباط از طریق هستههای CUDA و Streaming Multiprocessors (SM) برقرار میشود. در این مدل، مشکلات بزرگ به مجموعهای از بخشهای کوچک تقسیم شده و بهطور همزمان روی هستههای مختلف اجرا میشوند.
چرا CUDA مهم است؟
اهمیت CUDA را میتوان از دو دیدگاه بررسی کرد:
- سرعت بینظیر پردازش موازی: به دلیل تعداد بالای هستهها، پردازشهای پیچیدهای که روزها یا ساعتها روی CPU طول میکشیدند، روی GPUهای مجهز به CUDA در زمانهای بسیار کوتاهتر انجام میشوند.
- انعطافپذیری: برخلاف Shaderهای محدود در نسلهای قدیمی کارت گرافیک که فقط برای پردازش تصویر طراحی شده بودند، CUDA به توسعهدهنده اجازه میدهد هر نوع الگوریتم دلخواه را پیادهسازی کند.
جایگاه در صنعت
از روز معرفی CUDA، صنایع مختلف شروع به بهرهبرداری از آن کردند:
- پزشکی: پردازش تصاویر و شبیهسازیهای بیولوژیکی با دقت بالا.
- هوافضا: مدلسازی جریانهای هوا و شبیهسازیهای پرواز.
- مالی: تحلیل دادههای عظیم و الگوریتمهای پیشبینی بازار.
- سرگرمی و بازی: افزایش کیفیت رندر و افزودن جلوههای بصری پیشرفته.
CUDA نهتنها در کارتهای گرافیک دسکتاپ بهکار رفته، بلکه امروزه در سرورهای پردازشی، مراکز داده و ابررایانهها نیز حضور پررنگ دارد.
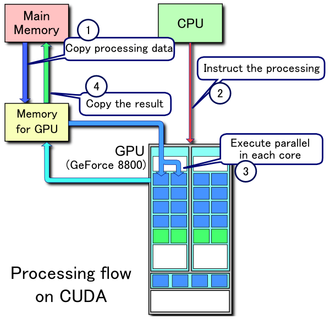
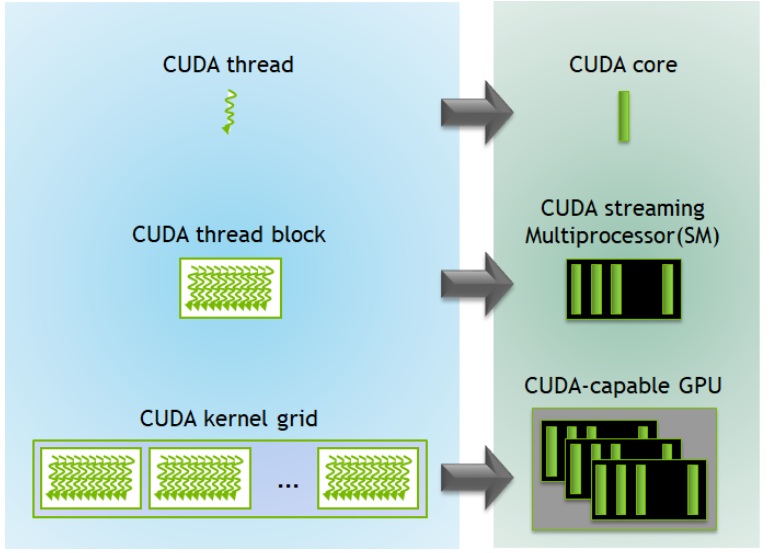
وقتی از «هستههای CUDA» صحبت میکنیم، باید درک کنیم که اینها بخشی از یک سیستم بزرگتر به نام GPU هستند. کارت گرافیک مجهز به فناوری CUDA در واقع یک مجموعه سختافزاری است که از هزاران جزء کوچک اما هماهنگ تشکیل شده و همه این اجزا برای یک هدف مشترک کار میکنند: اجرای سریع و موازی عملیات محاسباتی.
معماری پایه GPU و نقش هستههای CUDA
در دل هر GPU شرکت NVIDIA، بخشهایی وجود دارد که «واحدهای مالتیپروسسور جریانی» یا Streaming Multiprocessors (SM) نامیده میشوند. هر SM شامل تعداد زیادی هسته CUDA است، که هر هسته وظیفه اجرای یک رشته (Thread) را بر عهده دارد. میتوان SM را شبیه یک گروه کاری بزرگ در نظر گرفت که هر عضو آن (هسته CUDA) بخشی از کار کلی را انجام میدهد.
در سادهترین حالت، وقتی برنامهای با استفاده از CUDA نوشته و اجرا میشود، دادهها بهطور موازی بین هستهها تقسیم میشوند. این تقسیمبندی باعث میشود عملیات بزرگی که روی CPU باید پشت سر هم اجرا شود، روی GPU بهطور همزمان پیش برود.
اجزای اصلی معماری CUDA
معماری CUDA فقط به وجود هستهها محدود نمیشود، بلکه مجموعهای از اجزا و زیرسیستمهاست که با هم کار میکنند:
- هسته CUDA (CUDA Core)
واحد پردازشی اصلی که عملیات ممیز شناور (Floating Point) و صحیح (Integer) را انجام میدهد. هر هسته قادر است یک دستور را در یک چرخه زمانی اجرا کند. - واحد مدیریت رشتهها (Warp Scheduler)
وظیفه دارد دستهای از رشتهها (Threads) که معمولاً به گروهی ۳۲ تایی به نام «Warp» تقسیم میشوند را مدیریت کرده و برای اجرا برنامهریزی کند. - حافظه ثبتها (Registers)
هر Thread مجموعهای از رجیسترهای اختصاصی دارد که دادههای موقت در آن ذخیره میشوند. سرعت دسترسی به رجیسترها بسیار بالا است. - حافظه اشتراکی (Shared Memory)
این حافظه بین همه هستههای یک SM مشترک است و برای تبادل سریع دادهها بین رشتهها استفاده میشود. - حافظه جهانی (Global Memory)
بزرگترین قسمت حافظه در GPU که همه رشتهها میتوانند به آن دسترسی داشته باشند، اما سرعت آن کمتر از حافظه اشتراکی است. - واحدهای ویژه (Special Function Units)
این واحدها عملیات خاص و سنگینی مانند محاسبه توابع سینوس، کسینوس، ریشه دوم و … را با سرعت بالا انجام میدهند.
نحوه اجرای برنامه روی CUDA
وقتی یک برنامه CUDA اجرا میشود:
- ابتدا دادهها از حافظه اصلی سیستم (RAM) به حافظه GPU انتقال پیدا میکنند.
- سپس پردازش به شکل «شبکهای از بلوکها و رشتهها» (Grid of Blocks and Threads) تقسیم میشود.
- هر بلوک توسط SMها مدیریت شده و هر Thread با استفاده از یک هسته CUDA اجرا میشود.
- پس از پایان محاسبات، نتایج به حافظه اصلی سیستم برگردانده میشوند.
این مدل باعث میشود حتی میلیونها Thread قابل مدیریت و اجرا باشند.
مزیت تعداد بالای هستهها
برای درک اهمیت تعداد هسته CUDA، کافی است بدانیم که مثلاً کارت گرافیک سری RTX 4090 تعداد بیش از ۱۶ هزار هسته دارد. این تعداد به GPU امکان میدهد همزمان روی هزاران بخش از یک مسئله کار کند.
مثال ساده: فرض کنید میخواهید یک ویدئو با رزولوشن 8K را پردازش کنید. CPU با داشتن ۱۲ یا ۱۶ هسته، مجبور است بخشهای زیادی را به صورت ترتیبی اجرا کند، اما GPU با هزاران هسته CUDA، میتواند هر پیکسل یا گروهی از پیکسلها را همزمان پردازش کند، و کل عملیات را در مدت بسیار کوتاهی انجام دهد.
هماهنگی با زبانهای برنامهنویسی
CUDA در ابتدا با زبان C سازگار بود، اما امروز توسعهدهندگان میتوانند از زبانهایی مانند Python (با کتابخانههای NumPy و Numba)، Fortran، و حتی MATLAB برای نوشتن برنامه CUDA استفاده کنند. این انعطاف زبانی، استفاده از قدرت GPU را برای دانشمندان داده، مهندسان و توسعهدهندگان بازی آسان کرده است.
محدودیتها و چالشها
هرچند CUDA بسیار قدرتمند است، اما محدودیتهایی نیز دارد:
مقیاسپذیری: در مسائل خیلی کوچک، استفاده از CUDA ممکن است هزینه زمانی بیشتری نسبت به اجرا روی CPU داشته باشد.1920
وابستگی به سختافزار NVIDIA: CUDA فقط با پردازندههای گرافیکی ساخت NVIDIA کار میکند و این انحصار باعث شده برخی شرکتها به سراغ جایگزینهایی مانند OpenCL بروند.
مدیریت حافظه پیچیده: توسعهدهنده باید با دقت مسیر انتقال داده بین CPU و GPU را طراحی کند تا از کاهش سرعت جلوگیری شود.







نظر شما در مورد این مطلب چیه؟